
Pytorch Tensor Operations and Contiguous Array
Updated:
Pytorch의 Tensor 다루기
reshape, view의 차이점과 contiguous array
논문 재구현을 하면서, 어떤 때 reshape을 사용하고, 어떤 때 view를 사용하는지 가끔씩 의문이 들어서 이번에 해당 내용을 정리해보고자 한다.
먼저 공식 도큐먼트를 읽어보면,
torch.reshape(input, shape) → tensor
입력 tensor 와 동일한 데이터와 요소 갯수를 돌려주지만, 설정한 shape으로 바꿔버린다.
가능하다면 반환되는 tensor는 입력에 view를 수행한 것과 같지만, 아닐경우 원본을 copy한다. 여기서 말하는 view 수행 가능 조건은, Contiguous 한 입력과 호한가능한 stride(다음 element로 이동하기에 필요한 바이트 수)를 갖는 입력일 경우이며 이때에는 입력 tensor가 copy되지 않고 reshape(view)된다는 것이다.
그러나 copy 혹은 view를 수행할 것을 기대하고 이 함수를 사용하지 않는것이 좋다.
Tensor.view(*shape) → tensor)
reshape과 마찬가지로 다른 shape의 같은 데이터를 갖는 새 tensor를 “self” tensor로서 반환한다. (즉, 복제되지 않은 자기 자신)
새로운 view size는 원본 size와 stride에 대해 호환(compatible)해야 한다.
이에 대한 자세한 설명을 해보면 1) 새로운 view dimension은 original dimension의 subspace이거나, 2)아래와 같이 contiguous를 만족하는 [original dimension안의 특정 dimension들]만을 span하는 것이어야 한다.
$∀i=d,…,d+k−1,$
$\text{stride}[i] = \text{stride}[i+1] \times \text{size}[i+1]stride[i]=stride[i+1]×size[i+1]$
만약 위 두 조건 중 하나라도 만족하지 못한다면, (contiguous() 등을 통한) copy 없이 설정한 shape으로 “self” tensor를 view할 수 없다. 만약 view()가 수행될 수 있는지 여부가 불확실하다면, reshape()를 사용하는 것이 권장된다.
결국 tensor가 contiguous한지 여부에 따라 view가 수행되거나 그렇지 못할 경우 contiguous()와 같은 과정으로 copy를 한 후 shape을 바꿔준다는 것인데, 여기서 다시 ‘contiguous’한 tensor의 뜻이 궁금해졌다.
관련해서 스택오버플로우에 좋은 설명이 있었는데 (https://stackoverflow.com/questions/26998223/what-is-the-difference-between-contiguous-and-non-contiguous-arrays/26999092#26999092)
결국 array의 element들이 메모리상에서 어떻게 배열되여 있는가에 대한 내용이다. 어떤 array를 transpose를 해줄 경우 C-contiguous에서 Fortran-contiguous가 되므로, pytorch 관점에서 contiguity를 잃게 되고, 이때는 view를 사용할 수 없게 되는 것이다.

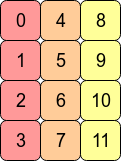
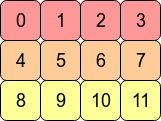
퍼포먼스 측면에서, 대부분의 경우 우리가 접근하는 메모리 주소가 인접하다면 처리가 더 빠른데 RAM에서 어떤 value를 가져올 때 인접한 주소의 것들이 같이 cpu에 캐싱되는 이유로 생각하면 될 것 같다. 즉 이미 contiguous한 array에 대한 operation이 요소들이 메모리상에 서로 떨어져 있는 array보다 더 빠른 연산이 가능한데, 같은 이유로 C-contiguous한 pytorch tensor에는 row-wise operation이 columnwise-operation보다 대체로 빠른 경향을 보인다고 한다.