
One-Stage Object Detection
Updated:
Overview
Object detection은 image classification에 비해서 더 까다로운 문제다.
Image classification은 이미지 안에서 주요한 물체가 어떤 것인지 classification을 하면 되지만, Object Detection은 하나 혹은 여러 물체들에 대하여 location과 classification을 동시에 수행한다.
일반적으로 Object Detection Model은 여러 Bounding Box들을 predict하는데, 이 Bounding Box들은 각각 하나의 물체를 찾고(location), 그 물체가 무엇인지 분류(classify)한다. 각각의 Bounding Box들에는 모델이 그 Bounding Box가 실제로 Object를 포함하는 것에 대한 신뢰정도를 표현하는 confidence score를 갖고 있다.
Object Detection이 어려운 이유중 하나는, 학습 이미지에서 Detect할 Object가 없거나 여러개가 될 수 있고, 모델 또한 여러 상자들을 predict 할 수 있다는 것이다. 이 때, 어떤 prediction을 ground-truth 상자와 비교하여 loss function에 넣어 줄 것인지 정하기가 어렵다. 실제 Object들의 개수에 비해 너무 많은 상자(Bounding Box)들을 예측할 때가 많은데, 이 때 사후처리로 일정 threshold 아래의 confidence score을 갖는 상자들을 filter out한다. 이를 Non-Maximum suppression, 줄여 NMS라고 한다.
NMS를 구하는 다른 방법은 Confidence Score이 가장 높은 상자와 겹치는 다른 상자들의 IOU를 각각 계산해서 IOU가 threshold(0.5 ~0.9)이상 상자들을 제거한다. 즉, confidence가 가장 높은 상자와 겹치는 부분이 큰 상자들을 제거하는 것이다.
Faster R-CNN과 같은 모델은 Object가 존재할 만한 후보 지역을 찾아내는 Regional Proposal을 수행하고, 이 지역들에 대해 각각 따로 prediction을 수행한다. 성능은 꽤 뛰어나지만, detection과 classification을 여러번 수행하기에 inference가 느리다는 단점이 있다.
반면 YOLO, SSD와 같은 one-stage detector의 경우에는, 신경망을 한번만 거치면 바로 상자들을 예측할 수 있다. 따라서 inference 속도가 매우 빠르고, 모바일 디바이스들에도 적용하기에 적절하다.
why object detection is tricky
classifier는 image를 입력으로 받고, 여러 클래스에 대한 확률 분포를 나타내는 하나의 출력을 가진다.
하지만 이 출력은 이미지 통째에 대한 간략한 요약정보에 불과하고, 이미지에 여러 물체들이 있을 때 잘 작동하지 않을 수도 있다.
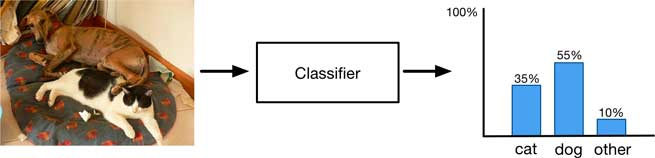
위 사진을 보면, classifier는 이미지에 대해서 “개일지도”, “고양이일지도”라는 정보를 알아챌 수는 있지만, 그게 전부다.

하지만, object detection모델에서는, 각각의 객체에 대해서 Bounding Box를 예측함에 따라 개별 물체가 어디에 있는지 알려줄 수 있다.
또한, detection 모델이 각각 상자에 대해서만 classify하기 때문에, 상자 밖에 있는 내용들에 무시할 수 있고, 따라서 각각 객체에 대해서 좀 더 confident한 prediction을 할 수 있다.
만약 데이터셋에서 ground-truth bounding box에 대한 annotation을 제공한다면, 모델 예측에 localization output을 쉽게 추가할 수 있다.
각각의 bounding box에 대하여 4개의 숫자(x,y,w,h)를 예측하면 된다.
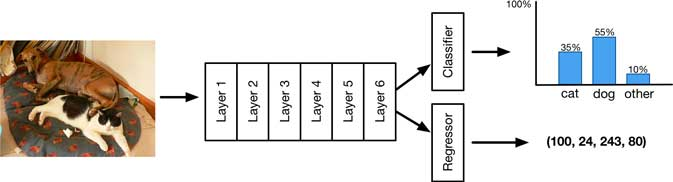
이제 모델은 두가지를 output으로 predict하게 된다.
- classification result
- bounding box
따라서 손실함수로 classification에 대해서는 cross-entropy loss를,
bounding box 좌표값에 대해서는 회귀문제 이므로 Mean-Squared-Error(MSE)를 사용한다. 두 loss를 하나로 합쳐 더해준다.
outputs = model.forward_pass(image)
class_pred = outputs[0]
bbox_pred = outputs[1]
class_loss = cross_entropy_loss(class_pred, class_true)
bbox_loss = mse_loss(bbox_pred, bbox_true)
loss = class_loss + bbox_loss
optimize(loss)
이렇게 결합된 loss를 SGD를 이용하여 학습시키면 잘 작동한다.
모델이 학습한 후 inference한 예시를 보자.

모델이 object(dog)의 class를 성공적으로 분류하고, 위치도 잘 잡은 것으로 나타난다. 빨간색 상자가 ground-truth이고 시안색 상자가 예측한 것이다. 둘이 완벽히 일치하지는 않지만, 근사하다는 것을 알 수 있다.
위 사진에서, 52.14%라는 score는 개일 확률이 82.16%라는 class score와 상자가 실제로 물체를 포함하고 있는지에 대한 confidence score 63.47%를 곱한 값이 된다. score = class score * confidence score
예측된 상자가 ground-truth과 얼마나 일치하는지 score을 계산하는 데는 두 상자의 IOU (intersection-over-union, jaccard index로 불리기도 함)를 계산할 수 있다. IOU는 0에서 1사이의 값을 가지며, 클수록 겹치는 부분이 넓다.
이상적으로는 IOU가 1이어야 하겠지만, 실제로는 0.5정도면 맞게 예측한 것으로 본다. 위 예시에서는 IOU가 0.749 정도이며, 이정도로도 두 상자가 잘 맞는다는 것을 확인할 수 있다.
regression output으로 하나의 상자를 예측하는 것은 좋은 결과를 준다.하지만, 이미지 분류 문제와 같이 이미지 안에 여러 object of interest가 있을 때, 잘 작동하지 않는다.

이 모델에서는 단 하나의 상자만 예측할 수 있으므로, 두 object 중 하나를 선택해야 맞지만, 상자는 엉뚱하게도 둘 가운데에 위치 하는 것을 볼 수 있다. 하지만 알고보면 모델이 내놓은 결과는 합당하다. 모델은 두 물체가 있다는 것을 알고 있지만, 줄 수 있는 output이 하나의 상자이므로, 타협해서 상자를 두 물체 사이에 위치시키게 된다. 상자의 크기도 마찬가지로 두 물체 크기의 중간 정도가 된다.
즉, 이 모델에서는 “첫번째 상자를 왼쪽에 있는 말에 두고, 두번째 상자를 오른쪽에 있는 말에 둔다.” 라고 할 수 있는 능력이 없다. 대신에, detector는 각각이 아닌 모든 object들을 예측하려고 한다. 또한, 모델이 N개의 detector들을 가진다고 하더라도, 그들은 하나의 팀으로 작동하지 않는다. 즉, 여러 상자를 검출하는 detector 역시 하나의 상자만을 예측한다.
따라서 우리는 Bounding Box를 specialize(분화)할 필요가 있다. 이를 통해 각 detector들은 각각 오로지 하나의 물체만을 예측하게 만들고, 다른 검출기들은 다른 물체들을 탐지할 수 있게 된다.
specialize 하지 않는 모델에서는, 각각의 detector가 이미지에 있는 모든 위치에 있는 모든 가능한 object에 대해서 탐지해야 하는데. 이건 이 모델의 능력을 벗어나는 일이다.. 결국 모델은 항상 이미지의 중앙으로 Bounding Box를 예측하게 되는데, 이렇게 해야 훈련 데이터셋 전체에 대한 손실을 가장 줄일 수 있기 때문이다.
YOLO, SSD, DetectNet과 같은 one stage detector들은 각각의 Bounding Box Detector을 이미지에서 특정한 위치에 대해 포지셔닝함에 따라 이러한 문제들을 해결할 수 있고, 이를 통해 detector는 특정 지역에 있는 object들에 대해 분화해서 학습할 수 있다.
Enter the grid
고정된 그리드를 사용하는 것이 이 “specialize”의 한 방법인데, one stage detector의 메인 아이디어이기도 하다. 그리드는 R-CNN과 같은 region proposal-based detector들과 차별되는 점이기도 하다.
그렇다면 이러한 모델의 가장 단순한 아키텍처를 생각해 보자. 여기에는 feature extractor(특징 추출기)의 역할을 하는 base network (backbone 이라고도 한다.)가 있고, ImageNet과 같은 데이터로부터 pretrain 되는 경우가 많다.
YOLO와 같은 경우, feature extractor 부분에서 416x416 크기의 픽셀 이미지를 입력으로 받고, SSD는 300x300크기의 이미지를 받는다. 이 픽셀 크기들은 보통 classification의 대상이 되는 입력 이미지들(보통 224x224 정도)보다 더 큰데, 이렇게 함으로써 이미지의 세부 디테일을 놓치지 않을 수 있다.

base network로 사용될 수 있는 것에는 제한이 없다. Inception, Resnet, Yolo 등을 사용하고, 모바일 환경에서는 가볍고 빠른 Squeezenet, Mobilenet 등을 사용한다.
이렇게 만들어진 feature extractor 위에, 우리는 몇 개의 컨볼루션 레이어를 더 얹을 수 있다. 이 레이어들은 bounding box들을 예측하고 object의 class probability를 구하기 위해 fine-tuned 된다. 이 부분이 모델에서 object detection을 맡는 부분이라고 할 수 있다.
Object detector을 학습시키기 위해 널리 사용되는 데이터셋들이 많이 존재하는데, 이 예시에서는 20가지의 class가 있는 Pascal VOC dataset을 활용하기로 한다. 그렇게 해서 신경망의 첫 부분(base network 혹은backbone)은 ImageNet을 이용해 학습하고, 두번째 부분(object detection을 맡는 부분)은 VOC를 사용한다.