
Data Augmentation in Computer Vision
Updated:

YOLOv4에 등장하는 “bag of freebies”에는 inference time에서 latency를 증가시키지 않으면서 모델의 성능을 증가시키는 여러 기술들이 있다.
모델의 inference time에 영향을 주지 않아야 하기 때문에, bag of freebies의 대부분은 data management와 data augmentation과 관계가 있다. 이 기술들은 training set의 품질을 개선시키고 데이터의 양을 증가시켜 모델이 예상하지 못했을 수도 있던 시나리오에 대해서도 학습시킬 수 있는 효과가 있다.
존재하는 데이터셋으로부터 새로운 training example들을 만들어내는 data augmentation은 가지고 있는 데이터셋을 잘 활용할 수 있는 방법이고, 최신 연구에서도 이 것은 검증되고 있다.
현실에서 일어날 수 있는 모든 시나리오에 대해서 이미지를 얻는 것은 불가능하지만, 얻어진 이미지들을 변형시켜 다른 상황들에 대해서도 훈련 데이터를 “일반화”시킬 수 있는 것이고, 따라서 현실에서 일어날 수 있는 다양한 상황에 대해서 인식을 가능하게 한다.
Distortion
Photometric Distortion - Brightness, Contrast, Saturation, Noise
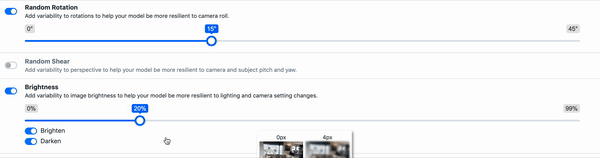
Geometric Distortion - Scaling, Cropping, Flipping, Rotating
Image 뿐만 아니라 Bounding Box들에 대한 정보들도 변형된다.
위 두 방법(Distortion)은 pixel값을 조절하는 것이므로, 변형된 이미지를
원본 이미지를 여러번의 transformation을 거쳐 다시 복원시킬 수 있다.
Image Occlusion
Random Erase - 이미지의 특정 위치를 random value 혹은 mean pixel value로 채우는 방법이다. 이 때, 이미지에 대한 지우는 영역의 비율이나 지우는 영역의 가로세로 비율을 바꿔가면서 수행하도록 구현한다.
기능면으로는, 이 것을 regularization 기법으로 볼 수 있으며, 따라서 모델이 훈련 데이터를 통째로 암기하고 overfitting 하는 것을 방지한다.

Cutout - training 단계에서 정사각형 영역을 mask 시킨다. 이렇게 cutout된 영역은 CNN에 들어가는 첫 레이어 이전부터 숨겨진다.
Random Erase와 매우 유사하지만, overlaid occlusion이 constant value로 채워진다는 것이 다르다. 목적은 마찬가지로 오버피팅을 방지하는 것이다.

Hide and Seek - 이미지를 S X S 개의 그리드로 나눈다. 각 그리드를 특정 확률(P_hide)에 따라 숨긴다. 이로 인해 모델은 object의 여러 부분들을 학습할 수 있게 된다.
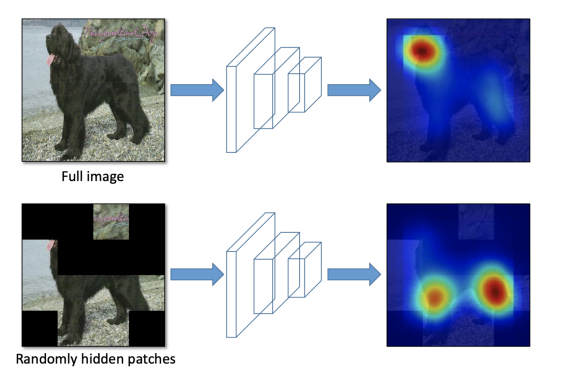
Grid Mask - 이미지를 그리드 패턴 아래에 숨긴다. Hide and Seek와 마찬가지로, 이것은 모델이 객체를 이루는 성분들에 대해서 학습할 수 있도록 한다.

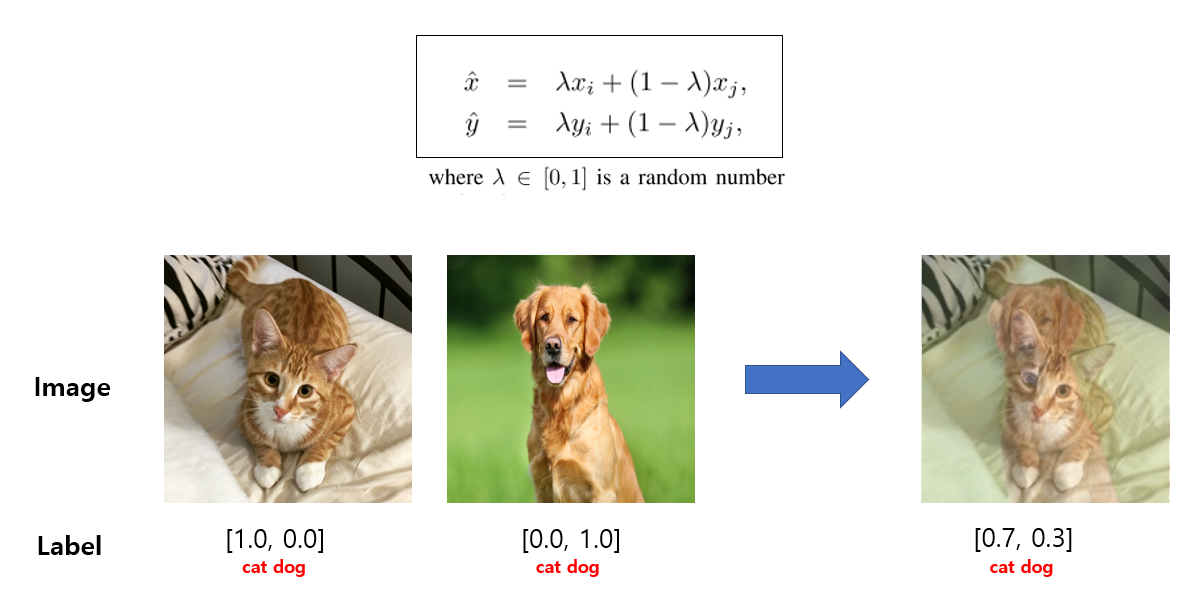
MixUp - 두 데이터의 이미지와 라벨을 weighted linear interpolation 하여 새로운 샘플을 생성하는 기법.
@https://towardsdatascience.com/data-augmentation-in-yolov4-c16bd22b2617