
Spatial Pyramid Pooling Network
Updated:
기존 CNN 아키텍쳐들은 input size가 고정되어 있었다. (ex. 224 x 224)
입력 이미지를 고정된 input size에 맞춰주기 위해, 이미지를 crop하거나 warping하는 과정이 필요했다. 이는 결국 이미지를 변형시키게 되는 것이므로 본래 이미지 정보를 온전히 담지 못한다는 단점이 있다.
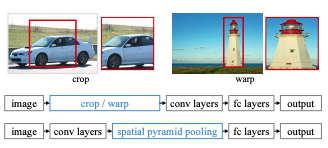
사실 convolution 필터들은 고정된 input size를 요구하지 않는다. 고정된 input size는 컨볼루션 레이어들 다음에 이어지는 fully connected layer가 고정된 크기의 입력을 받기 때문이다.
여기서 SPP*(Spatial Pyramid Pooling Network)의 개념이 제안되는데,
입력 이미지의 크기에 관계 없이 conv layer들을 통과시키고, fc layer를 통과하기 전에 피쳐 맵들을 동일한 크기로 조절해주는 pooling layer를 사용하는 것이다.
SPP 알고리즘
- 먼저 전체 이미지를 미리 학습된 CNN을 통과시켜 피쳐맵을 추출한다.
- Selective Search를 통해서 각각 찾은 RoI들은 제 각기 크기와 비율이 다르다. 이에 SPP를 적용하여 고정된 크기의 feature vector을 추출한다.
- 그 다음, fc layer들을 통과시킨다.
- 추출한 벡터로 각 이미지 클래스 별로 binary SVM Classifier를 학습시킨다.
- 추출한 벡터로 bounding box regressor를 학습 시킨다.