
Batch Normalization
Updated:
@https://arxiv.org/abs/1502.03167
Batch Normalization을 사용하는 근본적인 이유는 Gradient Vanishing / Gradient Exploding 이 일어나지 않도록 하기 위해서이다.
(Batch Normalization : Accelerating Deep Network Training by Reducing Internal Covariance Shift) 논문에 따르면,
Batch Normalzation은 training 과정 자체를 전체적으로 ‘안정화’(여기서 말하는 안정화라는 것은 Gradient Vanishing이나 Gradient Exploding을 막는다는 뜻으로 여겨진다.)하기 위한 방법이다.
Gradient Vanishing이 발생하는 이유는 Internal Covariance Shift 로 설명할 수 있다. Internal Covariance Shift는 Training 과정에서 각각의 layer들의 input distribution이 consistent하지 않은 현상을 말한다. 각각의 layer parameter (weight, bias)가 변할 때, 뒤에 있는 layer들의 input distribution도 변하기 때문에 나타나는 현상이다. input distribution shift는 신경망이 깊어질수록 더 문제가 생기게 된다.
이전에는 이를 막기 위해 Activation 함수를 ReLU를 사용하거나, careful initialization, small learning rate를 사용했으나, 이는 근본적으로 문제를 해결하기보다는 간접적인 방법에 불과했다. 또한 small learning rate를 사용한다는 것은 결국 학습에 소요되는 시간이 많다는 것을 의미하고, Gradient Vanishing / Gradient Exploding이 일어나지 않으면서도 빠른 속도로 학습을 할 수 있는 방법을 찾기 원한다.
그렇다면 internal covariance shift를 어떻게 줄일 수 있을까?
input distribution을 zero mean, unit variance로 가지도록 normalize 시켜 normal distribution으로 변형시킨다. 이것을 whitening 이라고 한다.
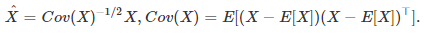
그러나 이런 naive한 approach에서는 크게 두 가지 문제점들이 발생하게 된다.
- multi variate normal distribution으로 normalize를 하려면 inverse의 square root를 계산해야 하기 때문에 필요한 계산량이 많다.
- mean과 variance 세팅은 어떻게 할 것인가? 전체 데이터를 기준으로 mean/variance를 training마다 계산하면 계산량이 많이 필요하다.
Batch Normalization은 이 두 문제를 해결하면서도 global differentiable하여 back propagation을 적용하기에 문제가 없게 한다.
Batch Normalization Transform
앞서 제시된 두가지 문제들을 해결하기 위하여 Batch Normalization은 두가지를 제안한다
- 각 차원들이 서로 independent하다고 가정하고 각 차원 별로 따로 estimate를 하고 그 대신 표현형을 더 풍성하게 해 줄 linear transform도 함께 learning한다
- 전체 데이터에 대해 mean/variance를 계산하는 대신 지금 계산하고 있는 batch에 대해서만 mean/variance를 구한 다음 inference를 할 때에만 real mean/variance를 계산한다.
위 방법에서는 모든 feature들이 서로 correlated 되었다고 가정했기 때문에, whitening 기법을 사용했지만, 각각 feature가 서로 independent 하다고 가정한다면, 단순 scalar 계산으로도 normalization이 가능하다.
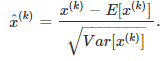
그러나 correlation을 무시하고 learning했을 때, 각각의 관계가 중요한 경우에 training이 제대로 되지 못할 수 있고, 이를 방지하기 위해 linear transform을 각각의 dimension마다 learning해준다. 이 linear transform은 scaling과 shifting이다.
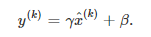
이때 ${\gamma}$, $\beta$는 학습 가능한 모델 파라미터이다.
그리고, 전체 데이터의 expectation을 계산하는 대신, 주어진 mini-batch의 sample mean/variance를 계산하여 대입한다.
Training Data로 학습을 시킬 때는 현재 보고있는 mini-batch에서 평균과 표준편차를 구하지만, Test Data를 사용하여 Inference를 할 때는 다소 다른 방법을 사용한다. mini-batch의 값들을 이용하는 대신 지금까지 본 전체 데이터를 다 사용한다는 느낌으로, training 할 때 현재까지 본 input들의 이동평균 (moving average) 및 unbiased variance estimate의 이동평균을 계산하여 저장해놓은 뒤 이 값으로 normalize를 한다.
